

Semantic Drift and the Layer Nobody Built

A metric owner changes one field on a Tuesday afternoon. Swaps a trailing 12-month average for a rolling 6-month window. Commits the change. Goes to lunch.
The number that comes out of that metric tomorrow will be materially different from the number that came out yesterday. But the trust score doesn’t know. It’s still carrying 1,200 interactions worth of confidence that were all formed against the old definition. The dashboard is green. The lineage is intact. The pipeline is healthy. Six months of behavioral signal just became irrelevant in a single commit.
Nobody downstream knows the ground shifted.
This is semantic drift. And it’s the failure mode the entire data infrastructure industry is ignoring.
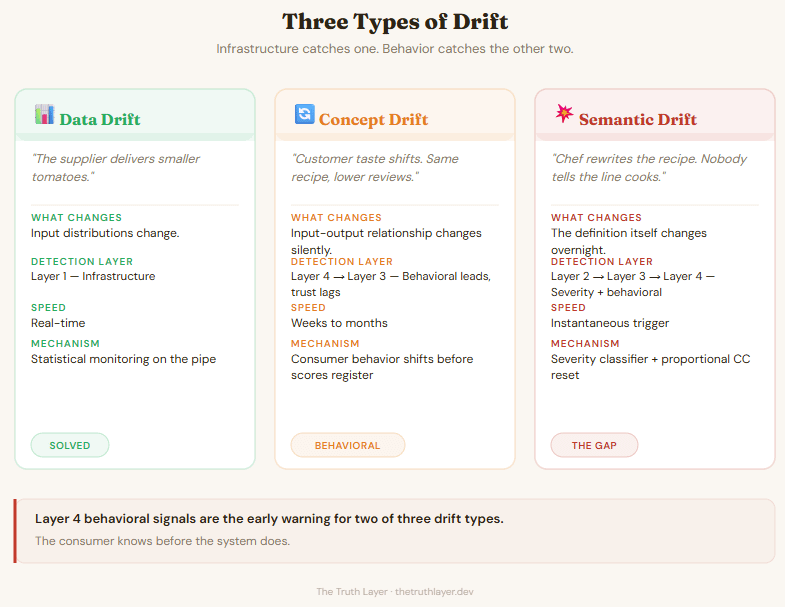
Three types of drift. Infrastructure catches one.
Think of it like a restaurant kitchen.
Data drift is when the supplier starts delivering slightly smaller tomatoes. Your recipe calls for six. You still use six. The dish is a little off. Your inventory system catches the weight discrepancy on the next delivery. Statistical. Mechanical. Solved.
Concept drift is when customers’ taste slowly shifts over a season. The recipe hasn’t changed. The ingredients haven’t changed. But the dish that earned five stars in January gets 3.5 by June. Nothing in the kitchen is broken. The relationship between what you’re making and what people want has quietly moved. You don’t notice until reviews pile up.
Semantic drift is when the head chef rewrites the recipe overnight and doesn’t tell the line cooks. They show up the next morning, follow the old muscle memory, and plate a dish that doesn’t match what the menu now promises. The kitchen runs smoothly. The ingredients are fresh. The output is wrong from the first plate.
The industry built monitoring for data drift. Statistical anomaly detection on the pipeline. Real-time, automated, mature. Databricks just shipped Unity Catalog Business Semantics with Anomalo for metric monitoring. The OSI coalition (Salesforce, Snowflake, dbt Labs) launched Open Semantic Interchange v1.0. AtScale is running conferences about it.
All of it operates at Layers 1 and 2. Infrastructure and semantic governance. Detect distribution shifts. Standardize definitions across tools. Ensure the pipe is clean and the vocabulary is consistent.
None of it tracks what happens after the metric is consumed.
The industry detects bottom-up. The truth layer detects top-down.
Bottom-up detection starts at the data and works upward. Is the pipeline healthy? Is the schema valid? Is the definition governed? If all three pass, the metric is declared trustworthy.
But all three can pass while a VP hesitates before acting on the number.
Rather than starting at the data and hoping trust follows, top-down detection starts at the consumer and works backward. What do people actually do when they receive this metric? Do they act without investigating? Do they pull raw data to verify? Do they investigate signals the score said were safe?
Consumer behavior is the leading indicator. The trust score is the lagging one.

Concept drift is invisible to infrastructure monitoring. The pipeline is working. The definition hasn’t changed. But usage patterns are quietly shifting. Teams that consumed the metric 400 times a month are down to 200. Analysts who used to act immediately are now clicking into lineage first. Shadow calculations appear where none existed before.
Those behavioral signals catch concept drift weeks before any trust score registers the impact. The consumer votes with their behavior before they file a ticket.
Semantic drift is even more acute. One commit invalidates all prior behavioral signal. Without a mechanism to classify the severity of that change and respond proportionally, the system silently carries stale confidence.
The severity classifier
Not all definition changes are equal. A description edit is cosmetic. A source table swap invalidates lineage, freshness monitoring, and every validation rule calibrated against the old data distribution. One field edit, three trust signals compromised.
The severity classifier counts the blast radius across trust signals. How many of the static signals does this change invalidate? And for each impacted signal, how deep does the dependency graph go?
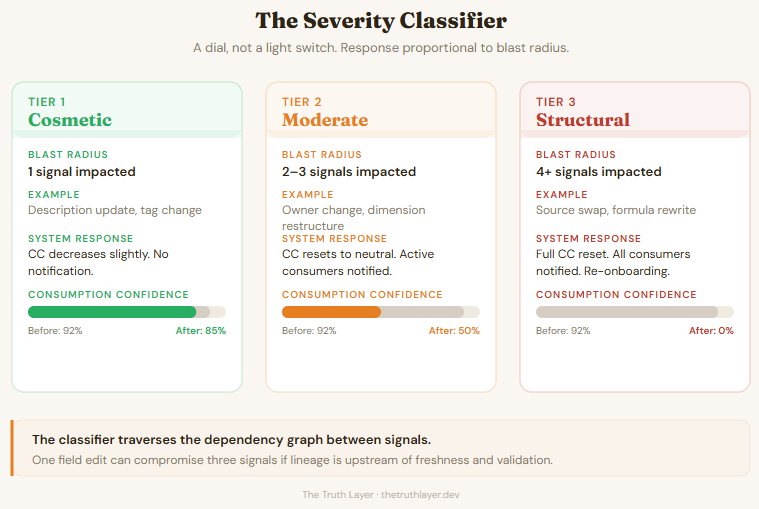
Tier 1 (cosmetic). One signal impacted. Description update, tag change. Consumption confidence decreases slightly. Score adjusts. No notification. New behavioral signal starts accumulating against the updated definition.
Tier 2 (moderate). Two to three signals impacted. Owner change, dimension restructure. Consumption confidence resets to a neutral baseline. Prior interactions are discounted, not deleted. Active consumers notified. The system says “this metric changed meaningfully. Your prior experience may not apply.”
Tier 3 (structural). Four or more signals impacted. Source system swap, formula rewrite. Full consumption confidence reset. Score recalculates from static signals only. All consumers notified with change summary. Prior behavioral data archived, not used for scoring. The metric essentially re-enters onboarding.
The response is proportional. Not a binary switch between “nothing happened” and “everything is broken.” A dial, not a light switch.
What the stronger semantic layer means for the truth layer
Databricks Unity Catalog. The OSI coalition. Anomalo. AtScale. They’re all strengthening the semantic foundation. Better governed definitions. More consistent vocabulary across tools. Standardized interchange formats.
This makes the truth layer more viable, not less relevant.
A stronger Layer 2 means the definitions arriving at Layer 3 are cleaner. Fewer reconciliation problems. Fewer variant conflicts. The trust layer spends less time catching governance failures and more time measuring what matters. Whether the governed, standardized, well-defined metric actually earns trust in the moment of decision.
The competitive boundary is clear. They tell you the data is fresh, the pipeline is healthy, and the definition is governed. They don’t tell you whether a VP hesitates before acting on it.
Consumption confidence as the detection layer
Behavioral signals catch two of three drift types before infrastructure does.
For concept drift. Usage divergence is the early warning. Two metrics answering similar queries. One declining. Teams are voting with their queries for which definition they trust. Shadow calculation spikes appear next. Consumption confidence drops not because the metric is wrong but because users retrieve it, hesitate, and pull raw data. Both signals accumulate over days and weeks. By the time the trust score adjusts, the behavioral layer has been flagging the problem for two weeks.
For semantic drift. The severity classifier fires immediately at the moment of definition change. But the behavioral validation that follows is what closes the loop. After a Tier 2 or Tier 3 change, does the new definition earn trust? Do consumers act on it without investigating? Or do they hesitate on a metric that used to be automatic? The severity classifier handles the instant response. Consumption confidence handles the ongoing verdict.
For data drift. Infrastructure catches it. Statistical monitoring on the pipe. The behavioral layer adds a complementary signal (consumers abandoning responses correlates with stale data) but infrastructure is the primary detector.
The pattern is consistent. Layer 4 behavioral signals are the early warning system for the two drift types that infrastructure can’t see. The consumer knows before the system does.

The gap nobody named until now
AtScale published an analysis this year saying the tolerance for semantic drift ran out the moment AI agents started consuming data. Agents don’t reconcile in meetings. They don’t call a colleague to sanity-check. They act on whatever the system returns.
Gartner now projects 60% of agentic AI projects will fail due to lack of AI-ready data. Up from 40% in the prior estimate. The crisis is accelerating.
Deloitte found that only 20% of enterprises achieved revenue impact from AI despite 86% increasing their AI budgets. The gap between investment and impact is the trust gap.
The industry named the problem. Semantic drift. Context failures. AI-ready data. What they haven’t built is the detection mechanism that works from the top down. The layer that watches the consumer instead of the pipe. The layer that classifies the severity of a definition change and responds proportionally instead of treating every edit as either nothing or catastrophe.
I’ve been building that layer. You can see what it looks like at thetruthlayer.dev.
This is the fourth article in “The Truth Layer” series. The first explored the trust crisis. The second showed what trust contracts look like. The third revealed the eval gap. This one found the drift nobody detects. The pattern across all four is the same. The industry builds Layer 1 and Layer 2 and stops. The truth layer is what happens when you keep going.
Databricks tells you the metric is healthy. The truth layer tells you whether anyone trusts it.