

The Calibration Gap: Why Your Trust Score Was Weighted by Feel

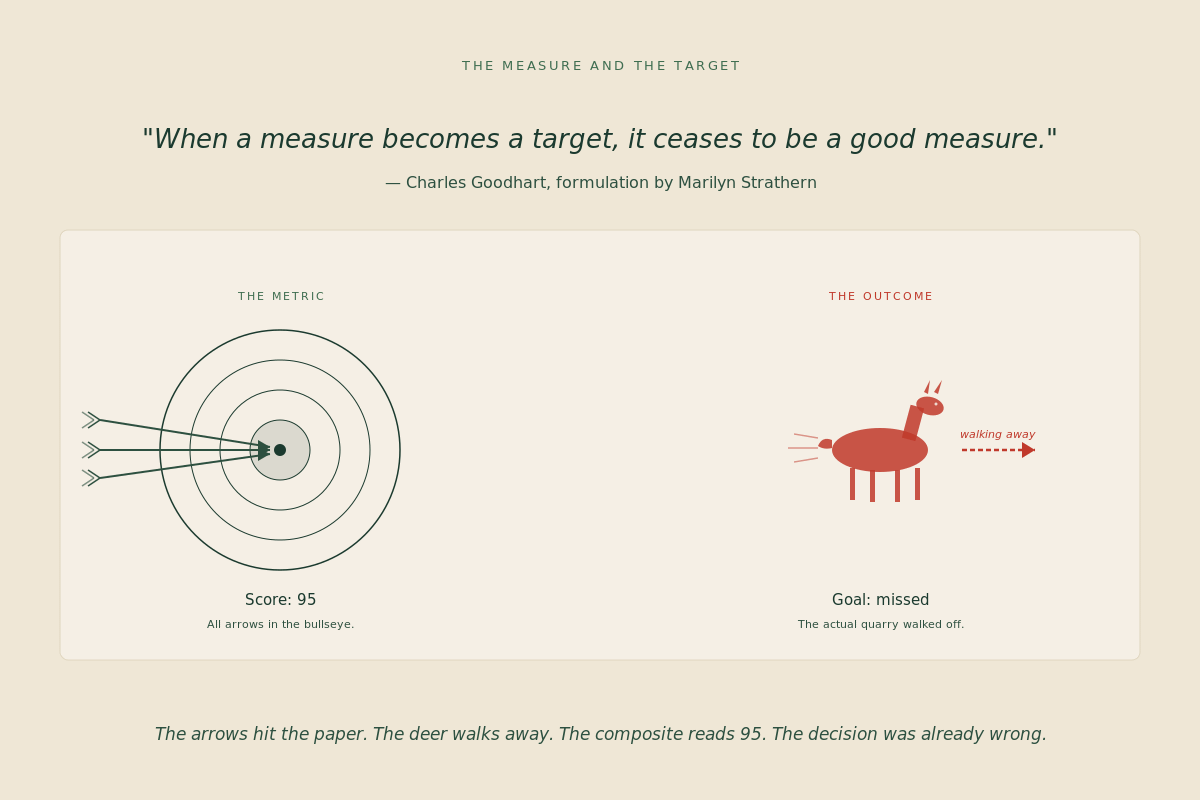
A car’s check engine light has been on for two years. The driver does not check the engine anymore. The light is stable. The light is honest at construction. The light is also worthless. Stability is not the same as truthfulness.
This is the gap inside every composite trust score running in production today.
A modern trust score is a composite of five signals. Lineage, where the number came from. Freshness, when it was last computed. Ownership, who is accountable. Usage, how widely it is consumed. Discoverability, what surrounds it. The signals get combined by feel. The composite ships. The agent acts on it. Almost nobody audits the weighting against realized outcomes.
When Klarna announced in February 2024 that AI could do the work of 700 customer service representatives, the company was reporting a capability score. The score said the AI handled 75 percent of chats in its first month. Cost and throughput were weighted heavily. Quality and customer satisfaction were not in the composite. By May 2025, CEO Sebastian Siemiatkowski reversed course and began rehiring humans. He told Bloomberg the company had let “cost as a too predominant evaluation factor” determine the architecture. The capability number was honest at construction. The weighting was wrong.
Zillow Offers ran the same shape in 2021. A confident pricing model bought tens of thousands of homes. The model’s predictions were never recalibrated against realized sale prices. When the housing market turned, the model kept buying. The Q3 inventory writedown was 304 million dollars and Zillow shut the program down on the same earnings call. Upstart Model 22 in 2025. An AI underwriting model overweighted negative macroeconomic signals and was never audited against realized loan outcomes. Approval rates collapsed. The stock fell 9.71 percent on November 5. The securities class action followed in May 2026. Three different industries. Three different decision domains. One repeating failure.
Three places, one gap
Calibration failures live in three places upstream of any agent.
The weighting function is the first place. Signals are combined by feel rather than by predictive power. The signal that always reads high and still claims weight is overweighted. The signal that varies and predicts is underweighted. Almost no architecture audits this.
The aggregation is the second place. When the composite ships as a single number, the consumer cannot see which signal is doing the work. A high score can be carried by four healthy signals while the fifth, the load-bearing one, is silently failing. Rarely audited in production.
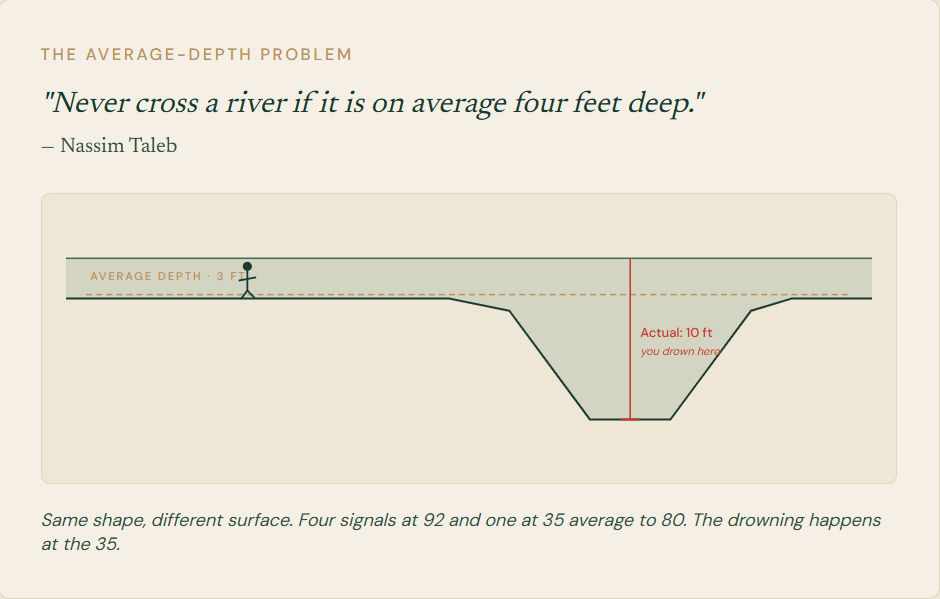
The time gap is the third place. The score was honest at construction and the world moved. Definition drift, regional reorganizations, schema rewrites. Most architectures cover this place with freshness flags and decay curves. Solved enough that the conversation has moved on.
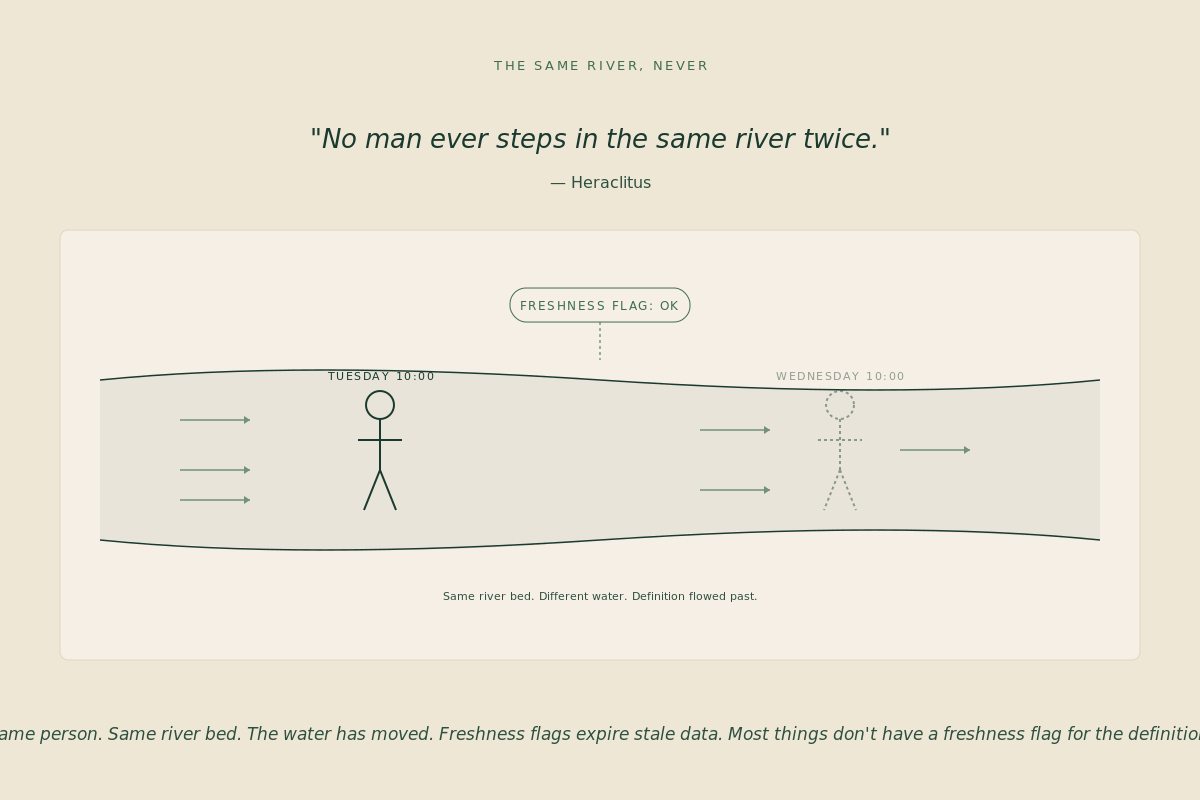
Rather than focusing on the time gap, which is the solved problem, I have been auditing the weighting function. The asymmetry of coverage is the architectural claim. Stable signals get mistaken for trustworthy ones. Noisy signals get mistaken for unreliable ones. The check engine light has been on for two years. The signal that varies and predicts is the one nobody reads anymore.
Stability is not the same as truthfulness.
What the audit looks like
The fix is structural, not parametric. The composite weighting function needs to be tied to outcomes. That means three moves.
First, list every signal that contributes to the composite. For each, find the last time its weight was changed. For each weight, find the outcome it was calibrated against. If the answer is “feel,” that signal is overweighted or underweighted by default. Second, pull realized outcomes from the last quarter and compare the predicted score to observed correctness. Third, rebalance.
I built an interactive at thetruthlayer.dev/calibration that walks through the three places with audit checklists per place. Place 01 carries the Klarna example expanded. Place 02 carries a silent pipeline break. Place 03 carries a definition drift after a metric owner change. Each opens a checklist a reader can apply to their own composite scoring.
The deeper move
The basic move is to ship a composite trust score and watch the dashboard turn green. The architectural move is to ask whether the weighting was right. The structural move is to build the audit into the architecture so the question gets answered every quarter without anyone filing a ticket.
Trust contracts carry the metric. The truth layer governs the contract. Calibration is the foundation under both. A trust score nobody audits against outcomes is a check engine light that has been on for two years. Decoration, not signal.
The composite shipped. The auditor never came. That is the gap.
Walk the three-place audit at thetruthlayer.dev/calibration.