

The Falsification Engine: What Ten Weeks of AI-Assisted Architecture Taught Me About the Architecture

I expected AI to make the work faster. It made the work different.
Ten weeks ago I had opinions about data trust. Today I have a published architecture with seventeen amendments, a Substack corpus, a locked brand system, and an interactive site. The output is real and the output is verifiable. The output is not what changed me about the work.
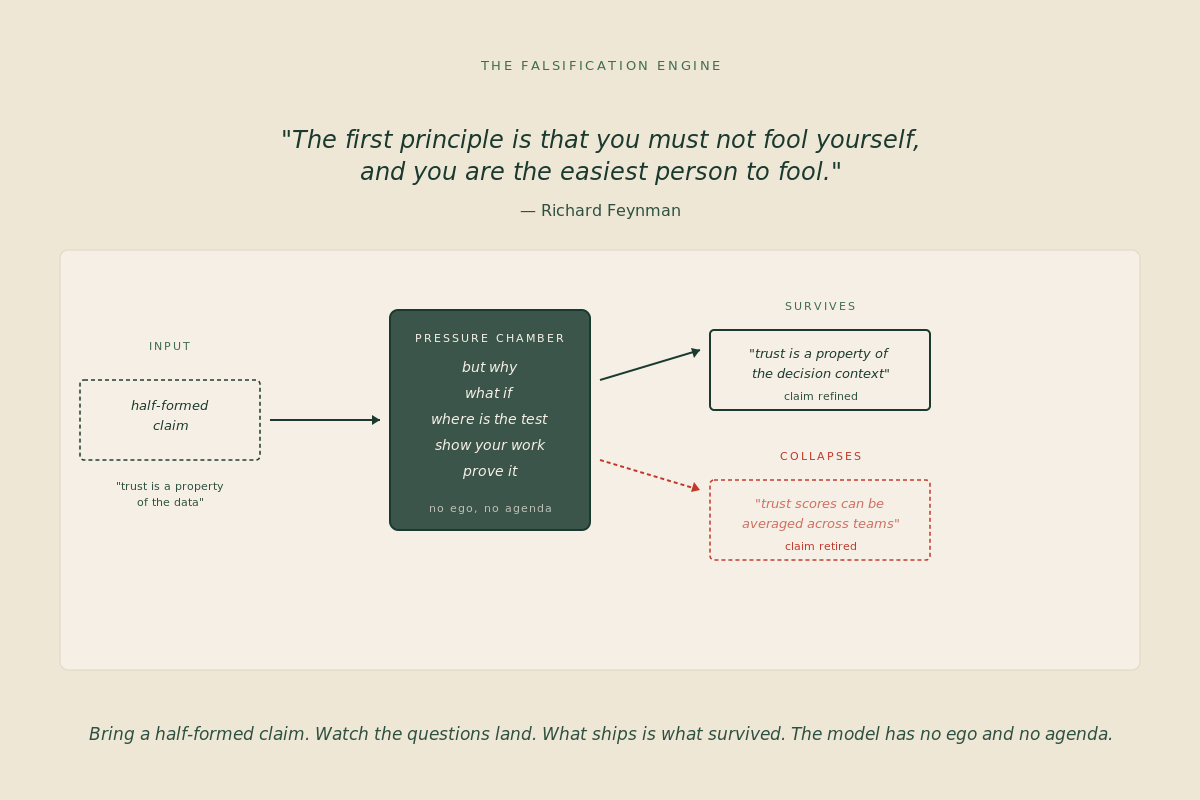
The change is upstream. I now do my best thinking in conversation. The conversation partner happens to be a model with no ego, no agenda, and no tolerance for the half-formed claim. AI is not a writing tool in this workflow. It is a falsification engine. Bring a half-formed idea. Watch the idea improve or collapse on the spot. What ships is what survived.
Feynman put the principle plainly seventy years ago. The first principle is that you must not fool yourself, and you are the easiest person to fool. The conversation partner makes the principle operational. I can describe a claim to a model that has not been on this project, has no commitment to my framing, and has nothing to lose by killing the claim. The model asks the question that would have killed the claim three months later in a leadership review.
Three claims that did not survive the pressure test

The trust contract architecture has seventeen amendments today. Three of them came from a single AI session where I described an architectural commitment and watched it collapse.
The first claim was that trust is a property of the data. That sounds reasonable for a paragraph and a half. The question that landed was simple. Is a stale-but-accurate number trustworthy. The claim collapsed in two minutes. The amendment that followed reframes trust as a property of the decision context. The data can be accurate and the decision can still be wrong because the context shifted.
The second claim was that trust scores can be averaged across teams to give a portfolio view. This one survived a paragraph longer because the math is easy. The question that landed was harder. What is the load-bearing weak signal in that average. The Taleb average-depth river runs through this whole architecture now because the claim could not hold. Averaging hides the drowning point. The amendment that followed treats every consumer of the composite as a separate calibration audience.
The third claim was that freshness flags solve the time-gap problem. This one was the cleanest collapse. The question was a single word. Definition. The freshness flag tracks the data, not the definition. A metric whose definition changed three weeks ago will read fresh on every signal that watches the pipe. The amendment that followed introduces a severity classifier for definition changes.
Three claims, three amendments. The amendments are mine and the architecture is mine. The questions that produced them came from a model that had no skin in any of the outcomes.
Why this works
There are three reasons the falsification engine works for architectural thinking, and one reason it does not.
It works because the model never tires of “but why.” A human reviewer, even a generous one, has a budget. After three rounds of why the conversation drifts toward agreement. A model has no budget. The seventh “but why” is identical to the first. Most architectural claims fail somewhere between the third and the sixth round. The model is the only reviewer who reliably gets there.
It works because the model has no commitment to your prior frame. A colleague who reviewed your last six docs has an updating prior that you make sense. The model has none. Every claim arrives fresh. The colleague extends grace; the model does not.
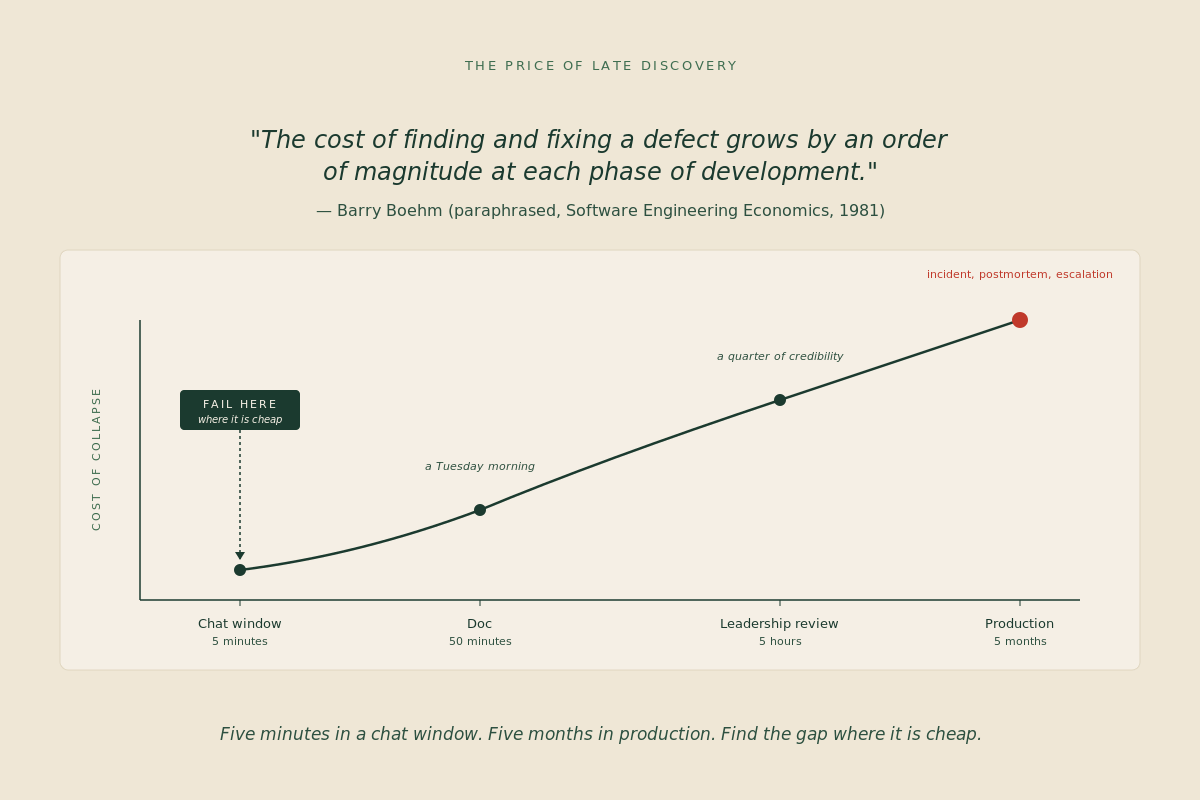
It works because the cost of collapse is zero in a chat window. A claim that collapses in a chat window costs five minutes of typing. A claim that collapses in a leadership review costs a quarter of your credibility. The pressure test is cheap exactly where you want pressure to be cheap.
It does not work as a writing tool in the conventional sense. The model can produce fluent text that says nothing. The job is to bring a claim and watch what happens to it, not to ask the model what to write. The output is the surviving claim, not the model’s prose.
The architecture is mine. The pressure test is mostly the model. Both names belong on the work.
What survived
Three things survived ten weeks of pressure testing that would not have survived without it.
The trust contract as a machine-readable artifact attached to the metric, not to the workbook or the dashboard. This claim got falsified twice and rebuilt three times before it held. The interactive version lives at thetruthlayer.dev.
The three-place upstream decomposition of calibration failures. The original framing had four places, then five, then six. The model pushed each one until only three remained. The remaining three carry the architecture without redundancy.
The architecture-versus-implementation distinction that underwrites the native dependence test. The original framing collapsed these two; the model pulled them apart through the Snowflake / Observe case.
You can walk the engine yourself at thetruthlayer.dev/falsification-engine. Three real claims, the questions that landed on them, and what each claim became after.
The deeper move
The basic move with AI is to ask it to write something for you. The architectural move is to ask it to break something you wrote. The structural move is to build the breaking into your daily process so that the question that would have killed your claim in production gets asked first by a model with no ego and no agenda.
The work got sharper because every claim had to survive a chat window before it landed in a doc. The architecture got cleaner because the model had nothing to lose by saying so. The corpus exists because the falsification engine ran every day for ten weeks.
The first principle is that you must not fool yourself. The second principle is that you should hire a reviewer who has no reason to let you.
See the engine in action at thetruthlayer.dev/falsification-engine.