

Three Weeks, Three Amendments: A Method for Stress-Testing Your Own Architecture

A senior finance analyst gives notice on a Wednesday. By Friday, three of her workbooks have stopped behaving the way leadership expects. Nobody changed the formulas. Nobody changed the data. What broke was the part of the architecture nobody had thought to draw.
This is not a story about a real analyst. It is a self-test, a scenario I ran through my own architecture to see what the architecture would do. The answer surprised me. The architecture broke in a place I had not been looking, and the fix did not require a single new primitive. It required reusing five things I had already built for a different purpose.
That self-test, the third in three weeks, is the reason I now think most architecture review is happening backwards.
How Architecture Usually Gets Reviewed
Most architects defend their designs to leadership. The flow is familiar. Design the system. Write the doc. Walk leadership through the diagram. Answer the questions. Get the green light. Build. Ship. Wait for production to find the gaps you missed.
Production finds gaps. That is a fact. 88 percent of agent projects fail before production, according to LangChain’s 2025 survey of 1,300 practitioners, and the survivors fail their first incident. The eval gap reinforces the point. 89 percent of teams trace every tool call. Only 37 percent run production evaluations on whether the agent’s action was correct. Most of the gaps that kill these systems are not gaps in the implementation. They are gaps in the design that nobody noticed because design review never put the architecture under load.
The flow gets the order wrong. Architecture goes to production carrying assumptions that should have been falsified at the whiteboard.
Catching a gap at the whiteboard costs a Tuesday morning. Catching the same gap in production costs a hundred times that, plus the incident. Boehm’s research nailed this thirty years ago and IBM confirmed it again. The cost of a missed assumption compounds with every phase you let it travel through. Self-test is the cheapest possible review because it happens before any cost gets baked in.
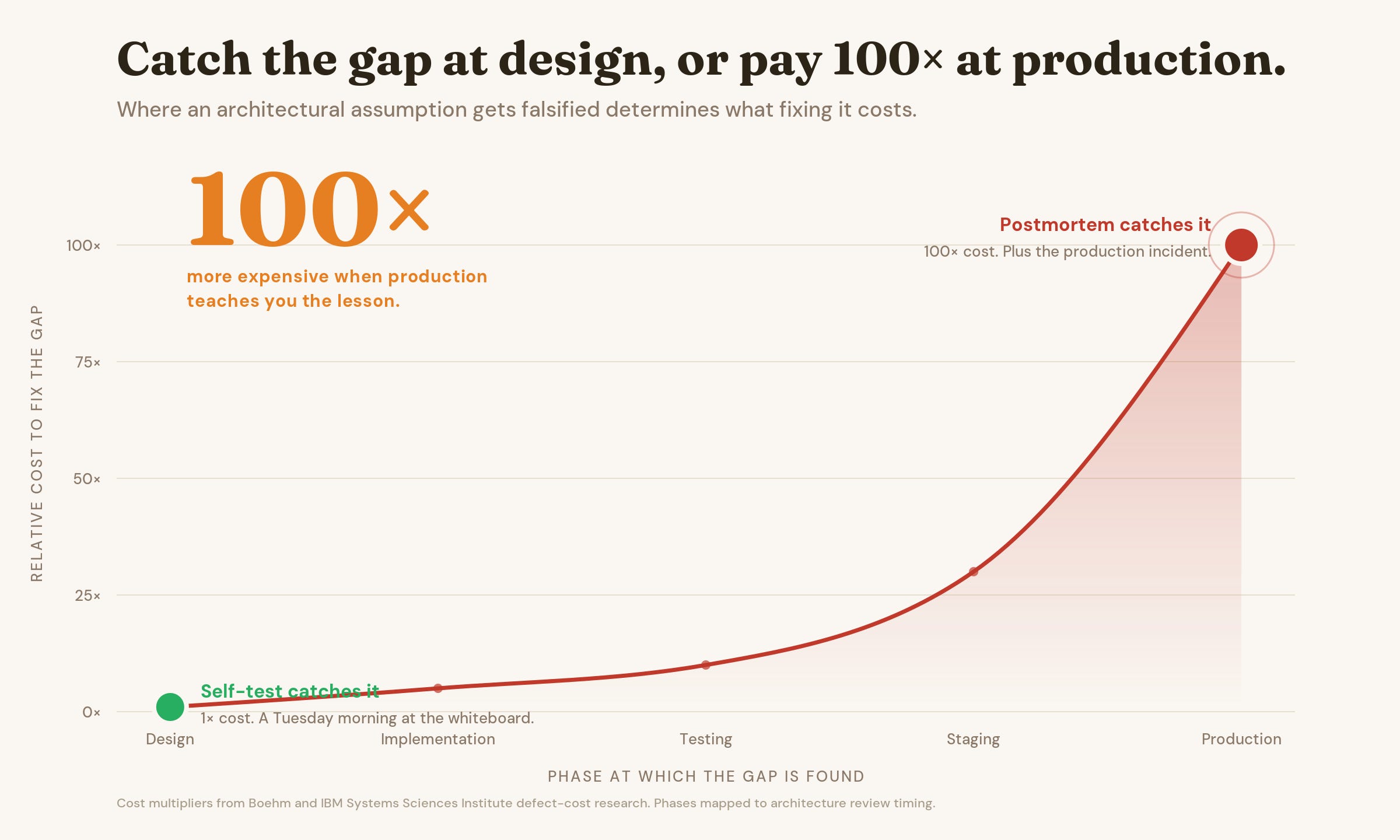
Engineers who run chaos engineering already know this in a different register. The point is not to break the system in production to learn whether it breaks. The point is to break it in a controlled environment so production does not have to teach you the lesson at scale. Self-test does the same thing one layer up. Not against the running system. Against the design.
Three weeks ago I ran a scenario through my architecture for the first time. Not to validate it. To break it. I did not expect the method to be repeatable. After three weeks and three amendments, I am convinced it is the only review that matters.
The Self-Test Method
A self-test is not a postmortem. It does not start with something that already happened. It starts with a realistic failure scenario, runs that scenario through the architecture as currently designed, and watches for the moment the architecture cannot produce a coherent response.
Four properties make it a method instead of an exercise.
First, the scenario is grounded in real consumer behavior. Not “what if everything fails.” Specific. Named. Believable inside the team.
Second, the architecture handles the scenario as currently designed. No future state. No “we will add this later.”
Third, the point of failure produces an amendment, not a redesign. The amendment must reuse existing primitives, or it does not count.
Fourth, the amendment is observable. It lives in the architecture doc, or it produces working code that proves the design.
Reusing existing primitives is the part that separates a self-test from a feature request. If your scenario surfaces a gap and the only fix is a new primitive, your scenario probably revealed a scope expansion the architecture was not designed to absorb. That is also useful information. It is just a different kind of useful.

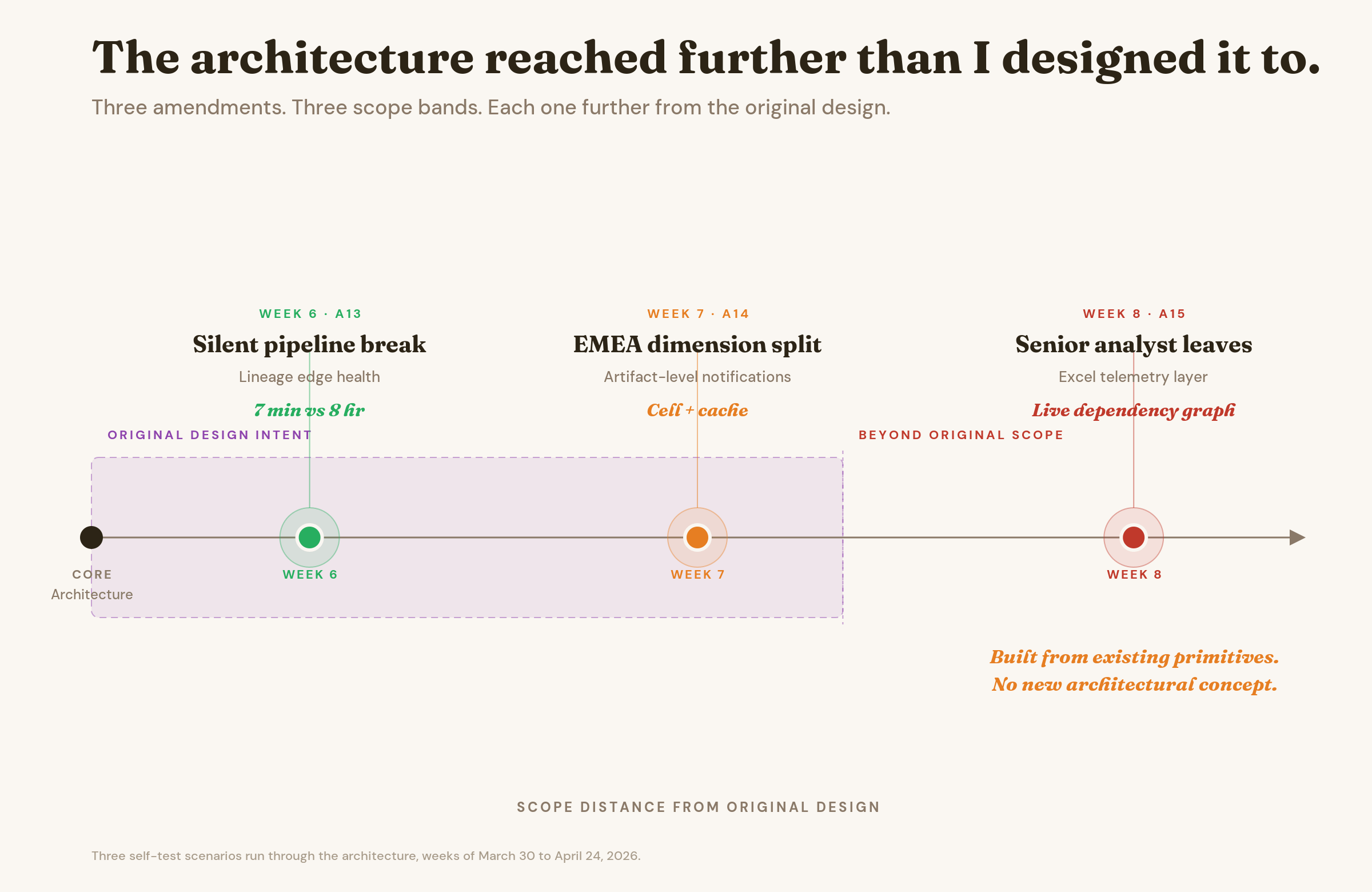
Three Self-Tests, Three Amendments
The first self-test was a silent pipeline break. The trust contract continued to render green because every signal it watched stayed green. Governed metric. Healthy lineage. Freshness flag pointed at the last successful run, which was technically accurate. The data underneath was simply absent. Seven personas hit that metric over the next eight hours before anyone noticed.
The fix integrated infrastructure-level lineage edge health into the trust contract. The truth layer does not replace infrastructure monitoring. It translates infrastructure events into trust impact. A pipeline edge that stops firing now lowers the consumption confidence signal within seven minutes instead of eight hours.
The second self-test was an EMEA dimension split. Finance reorganized regions, and overnight a dimension that had been one entity became two with overlapping definitions. The metric stayed green because metric-level trust contracts do not watch dimension structure. Cached dashboards downstream continued to render with the old dimension shape.
The fix made dimensions first-class trust contract objects with their own severity classifier, and added artifact-level notifications for cached and derivative surfaces. Cell-level trust contracts cover the live render. Artifact-level notifications cover the cache.
The third self-test was the senior analyst departure. The senior analyst leaves. Three of her workbooks reference governed metrics through Excel formulas the truth layer does not see. A definition change happens to one of those metrics. The workbooks compute confidently with stale logic. There is no stack trace. There is no broken pipeline. There is just a quiet drift in numbers that leadership cannot tell from a real change.
This is the failure mode of inheriting a recipe without the cook. The ingredients are right there. The instructions are right there. What’s missing is the practitioner who knew which step needed a softer hand on Tuesdays. The workbook keeps cooking. The dish slowly stops tasting like itself, and nobody can point at exactly when it changed.
The fix added a lightweight Excel telemetry layer that emits four events on cells touching governed metrics. Registration. Formula change. Dependency broken. Downstream reference added. The architecture builds a live dependency graph per workbook. The graph carries its own confidence signal that decays with verification staleness.
Three amendments in three weeks. Each one reused primitives that already existed. None of them required a new architectural concept.
The Pattern That Matters
The reason the third one matters more than the first two is what it stress-tested. The first amendment fixed a scenario the architecture was designed to handle and was missing the right hook for. The second fixed a scenario adjacent to the original scope. The third fixed a scenario outside the original scope entirely. A senior analyst leaving is not a data platform failure mode. It is a staff transition that exposes a knowledge transfer gap. The fact that the same primitives that govern metric lineage and detect behavioral drift produced a coherent amendment for that scenario is the proof that the architecture has absorbed the underlying problem, not just the visible problem it was built around.
That distinction matters. An architecture that handles what it was designed for is fit for purpose. An architecture that absorbs problems beyond its original scope is a system with grammar. New ideas expressed in that grammar feel inevitable rather than invented. That is when you know the architecture is right.
Why I Will Keep Doing This
I do not run self-tests because I expect them to fail. I run them because the only architecture review that matters is the one that happens before leadership has a reason to ask why production broke. Three weeks ago I had a method I was using for the first time. Today I have three amendments in the doc and a working prototype validating the third.
The next self-test is already scheduled. I will let you know what breaks.
See the truth layer in action at thetruthlayer.dev