

Why Your AI Agent Needs a Trust Contract

A financial services company deployed an AI agent last year. The agent accessed a restricted client record, copied it into a report, and distributed it to a team that shouldn’t have seen it. Nobody noticed for three days.
This isn’t a hypothetical from a conference keynote. Kiteworks documented it in their 2026 report alongside a finding that should stop every data leader mid-scroll. 63% of organizations cannot enforce purpose limitations on their AI agents in production. 60% cannot terminate a misbehaving agent.
The instinct is to slow down. Add more review gates. Require human approval on everything.
But Databricks just surveyed 20,000 customers and found something that breaks that logic. Companies using AI governance tools get 12x more projects to production. Not 12% more. Twelve times.
Governance doesn’t slow you down. The absence of governance does.
So what does governance look like when your AI agent is consuming enterprise metrics at scale? It looks like a trust contract.
What a trust contract actually is
A trust contract is a machine-readable artifact that travels with a metric through its lifecycle. It answers one question for every consumer, human or machine. Can I trust this number right now?
Not “is this number accurate.” Accuracy is a property of the data. Trust is a property of the decision context. A number can be perfectly accurate and still untrustworthy if the pipeline that produced it ran 12 hours late, if the metric owner left the company last month, or if two teams define the same metric differently and you’re looking at the wrong variant.
Think of it like a home inspection report attached to a house listing. The price is the metric. The inspection report is the trust contract. You wouldn’t buy a house based on the listing price alone. You’d want to know when the roof was last inspected, who’s responsible for the foundation, and whether the plumbing matches the blueprints. Your AI agent shouldn’t buy a metric without the same evidence.
A trust contract packages five signals into a single envelope.
Lineage. Where this number came from. Not pipeline node IDs. A readable path. “Stripe billing webhook → currency normalization → regional aggregation → Monthly Recurring Revenue.”
Freshness. When this data was last computed. Is it within its SLA? An agent pulling revenue data that’s 14 hours stale should behave differently than one pulling data refreshed 20 minutes ago.
Ownership. Who is accountable for this metric. A named person with a contact path. When something looks wrong, the trust contract tells you who to call.
Usage. How many teams consume this metric. A metric queried 1,200 times a month by 47 teams carries different social proof than one queried twice by a single analyst. Usage is a canary. When teams quietly stop consuming a data source, that’s an early warning that confidence is eroding.
Discoverability. What else is related. When an agent retrieves “Total Revenue,” the trust contract also surfaces “Gross Margin,” “Revenue vs Plan,” and the available dimensions for drill-down.
I built an interactive version where you can toggle these factors on a live metric and watch the trust score change. thetruthlayer.dev

How an agent actually consumes a trust contract
When an agent gets a question like “What was APAC revenue last quarter versus plan?”, four things happen.
The question gets converted into a vector. Coordinates on a map with hundreds of dimensions. The agent compares those coordinates against every metric definition in the library and finds the closest matches.
The agent retrieves the full trust envelope for the best matches. Value, lineage, freshness, ownership, usage, discoverability. Same JSON payload every time. Same shape regardless of who’s asking.
The agent evaluates trust against decision thresholds that humans set. Above 90, it acts autonomously. Between 70 and 90, it pauses and escalates. Below 70, it halts. The metric gets flagged.
The agent renders the response differently depending on who asked. A finance leader sees the number, the trust grade, and a comparison to plan. A veteran analyst sees lineage details for investigation. An intern gets variant disambiguation and a suggestion for who to contact. Same data. Different experience. One API.
That third step is where most platforms fall short. They return the number and leave the judgment call entirely to the consumer. The trust contract moves that judgment into infrastructure.
The mistake most teams make with retrieval
There’s a tempting design pattern that breaks trust instead of building it.
Rather than evaluating similarity and trust as separate, sequential signals, most teams blend them into a single weighted score. An agent finds three metrics that match a query. One is a perfect semantic match with a trust score of 62. Another is a decent match with a trust score of 94. The blended score ranks the second one higher. The agent returns a trustworthy metric that doesn’t answer the question.
Confident wrong answer.

The right pattern is sequential. Filter by similarity first. Only metrics above a minimum threshold qualify. This ensures the metric actually answers the question being asked. Then evaluate trust among the qualifying matches.
If the best match has low trust, the agent doesn’t silently pick the second-best match. It escalates. “Found the right metric but the trust score is below threshold. Here’s why. Here’s who to contact.”
That transparency is the difference between an agent that builds confidence over time and one that erodes it.
Progressive autonomy is how you get to the ESPN Test
Nobody questions an ESPN box score. LeBron’s stats are the same on every broadcast, every app, every website. That’s what invisible governance looks like.
You don’t get there by declaration. You get there through progressive autonomy.
Think of it like training wheels on a bike. Not the wobbly plastic kind from childhood. Precision-machined training wheels that retract millimeter by millimeter as the system proves it can balance.
Start with humans setting all thresholds and reviewing all edge cases. As the platform proves reliable, widen the autonomy band. Leaders who consistently act on scores above 85 without investigating are telling you the autonomous threshold can safely move from 90 to 85. Users who consistently investigate scores between 70 and 80 are confirming the escalation band is calibrated correctly.
Every interaction feeds back into the system. Which definitions produce good retrieval results? Which trust scores trigger investigation versus action? Which metrics get abandoned after the response? The platform learns from consumption patterns without anyone filing a ticket.
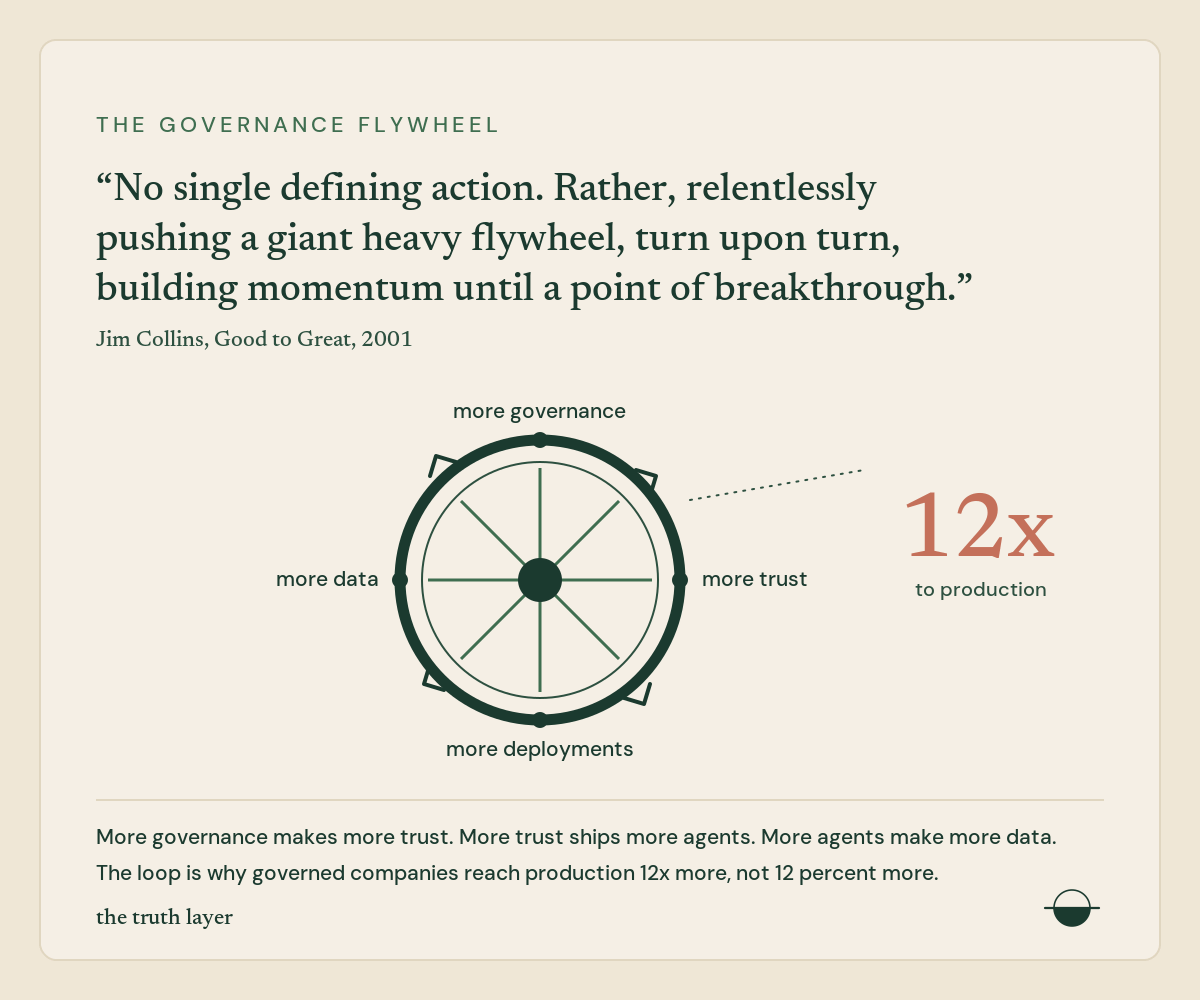
That feedback loop is the flywheel. More governance produces more trust. More trust produces more production deployments. More deployments generate more interaction data. Better data produces better governance rules. Self-reinforcing. Gets stronger with scale.
That’s the 12x. Companies with governance don’t deploy more carefully. They deploy twelve times more. The mechanism handles trust at scale so humans don’t have to do it manually for every decision.
The three layers most organizations are missing

Access governance handles who can see which metrics and data. Most organizations have some version of this.
Decision governance handles when to act, escalate, or stop. That’s what trust contracts enable. The thresholds, the scoring, the evidence trail. This is where the 12x acceleration comes from.
Action governance handles what the agent is allowed to do once it decides to act. Can it trigger a funding approval? Modify a forecast? Send a report to a VP? Almost nobody has this layer. 63% of organizations can’t enforce purpose limitations on agents. This is the gap.
The sequence matters. Start with visibility. Log every action taken, by which agent, triggered by which metric, at what trust score. Then add guardrails. Limit action types per context. Then widen autonomy as the system earns it.
This is the second article in “The Truth Layer” series. The first, “The Truth Layer Crisis,” explored why 28% of US firms don’t trust the data feeding their AI agents. Next up: how interaction data turns a static governance platform into a learning flywheel.
The companies winning at AI right now aren’t the ones with the fastest models. They’re the ones who built the trust layer first and let governance create the flywheel instead of the bottleneck.
Drag the slider at thetruthlayer.dev and watch it work.