

The Eval Gap: Why Agent Observability Isn’t Enough

It’s the 3 AM page that never fires.
Every health check passes. Latency nominal. Token costs stable. Tool selection accurate. Reasoning chain logged. The observability dashboard is green across the board.
But the pipeline that feeds your revenue metric broke 14 hours ago. The agent is serving yesterday’s number as today’s truth. And nobody notices. Because nothing in the monitoring stack was watching the data. Only the agent.
This is the gap the entire observability industry is ignoring.
The 57-point gap between belief and execution
Galileo surveyed AI teams and found something that should make every data leader uncomfortable. 72% believe comprehensive testing drives reliability. Only 15% achieve elite evaluation coverage. That’s a 57-point gap between knowing evaluation matters and actually doing it.

LangChain’s State of AI Agents report (1,300+ professionals) confirms the pattern from a different angle. 89% have agent observability. 62% have detailed tracing. But only 37% run online production evaluations. And nearly 30% aren’t evaluating at all.
Everyone is instrumenting. Almost nobody is evaluating.
You wouldn’t judge a doctor by how fast they write the prescription. You’d judge them by whether it’s the right one. But that’s exactly what agent observability without evaluation gives you. Speed metrics. Efficiency metrics. Zero quality metrics on the information the agent used to make its decision.
Two gaps, not one
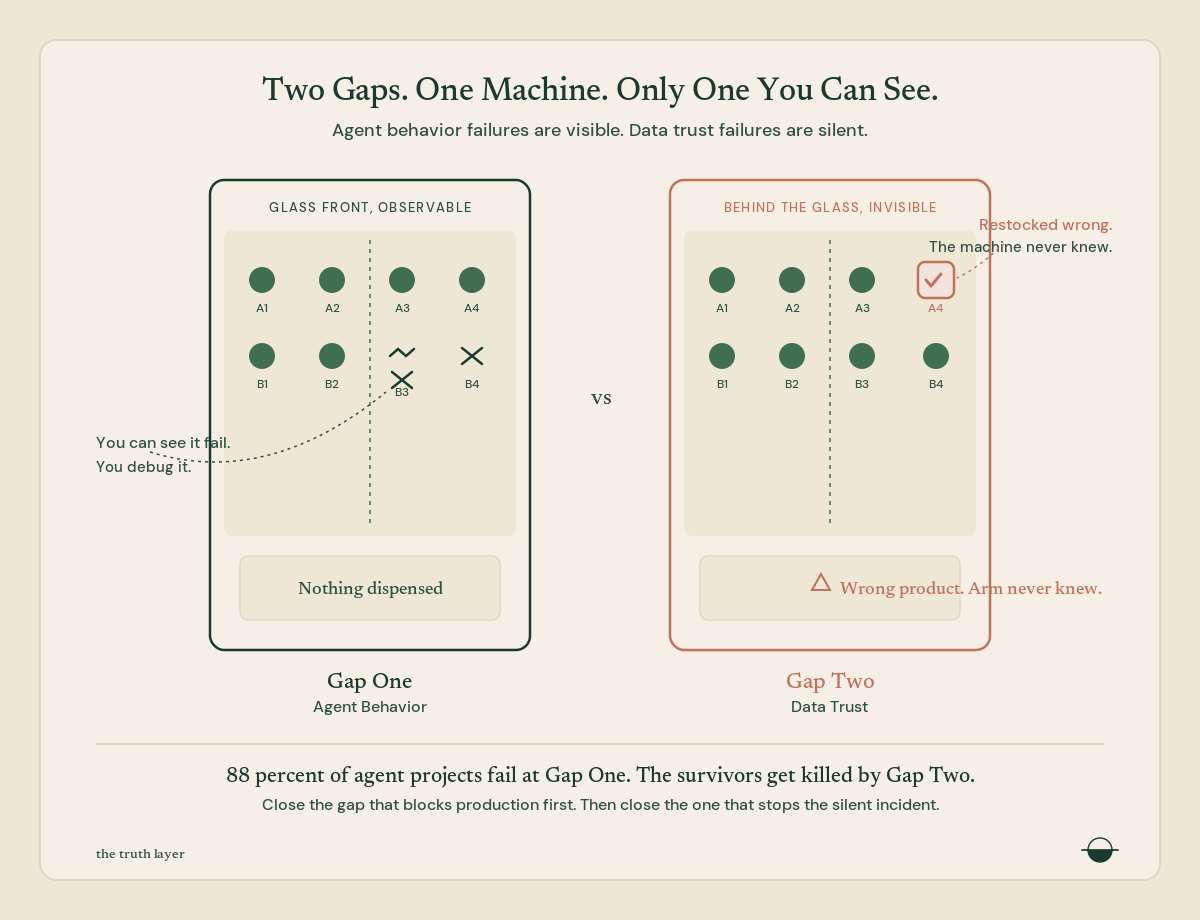
Rather than treating this as a single evaluation problem, I think about it as two distinct gaps stacked on top of each other.

Gap one is agent behavior. Did the agent call the right tool? Follow the right reasoning chain? Respond within latency thresholds? The observability vendors are building for this. Arize, Galileo, Langsmith, Dynatrace. It’s testable in staging. When it fails, it’s expensive but recoverable. You fix the prompt, retune the routing, redeploy.
Gap two is data trust. Was the information the agent acted on actually trustworthy? Did the trust signals correspond to reality? This is the gap almost nobody is building for. It’s not testable in staging because the data is fine in staging. It’s only visible in production, where the consequences are real.
Gap one failures are annoying. Wrong tool called. Slow response. Malformed output.
Gap two failures are career-ending. A VP makes a funding decision on data from a pipeline that broke overnight. The trust score said 90. The observability dashboard was green. The agent did its job perfectly. The data lied.
Digital Applied surveyed 650 leaders and found that 88% of agent projects fail before production. That’s gap one. The industry is pouring resources into fixing it. But the agents that survive? A researcher embedded in 20 companies deploying AI agents found that most had no rigorous evaluation process. Teams couldn’t tell whether their agents were operating at 60% accuracy or 90% until the 60% ones caused an incident.
“We’ll know if something goes wrong” is not an evaluation framework. It’s a prayer.
The same architectural mistake, repeated
The industry is making the same mistake with agent evaluation that it made with data platforms.

Data platforms built infrastructure (ETL, orchestration, storage) and semantics (metric definitions, metadata, catalogs). Then they stopped. Nobody productized the confidence layer. That’s the gap I wrote about in the first article in this series.
Agent evaluation is following the same path. Infrastructure (tracing, logging, token counting) is mature. 89% have it. Semantic evaluation (tool selection, reasoning chains) is partial. About 37% do it in production. Trust evaluation (calibration, decision boundary crossings, failure signals) is almost nonexistent.
Layer 3 is where the catastrophic failures happen. And Layer 3 is where the industry stopped building.
What calibration actually means
When your trust score says 85, is the metric actually trustworthy 85% of the time?
Most teams measure adoption. Are people using the platform? That tells you the system is running. It doesn’t tell you the system is right. Coverage and convergence confirm the platform is working. Calibration confirms the trust signals are telling the truth.
The problem is that nobody labels “correct trust score = 73.” You can’t observe ground truth directly. Your five signals (lineage, freshness, ownership, usage, discoverability) are proxies for trustworthiness, not trustworthiness itself. All five can look green while the metric has a formula bug overstating revenue by 4%.
So ground truth comes from failure signals, not success metrics.
Internal backtesting catches when your system disagrees with itself over time. Recalculate scores retroactively. Flag actions taken when the score later changed significantly. If a VP acted autonomously on a metric that crossed a decision boundary 48 hours later, that’s a calibration failure worth investigating.
External failure signals catch when reality disagrees with your system. Slack messages saying “that number is wrong.” Shadow spreadsheets where analysts pulled raw data instead of trusting the governed metric. QBR delays caused by metric disputes. Pipeline breaks the freshness signal missed.
It’s the difference between precision and accuracy. Internal backtesting is precision. External failure signals are accuracy. You need both.
The decision boundary model

Not all calibration gaps are equal. A trust score drifting from 92 to 83 while both scores are in the “auto-act” band doesn’t change any behavior. A score drifting from 75 to 65, crossing from “escalate” to “halt,” changes everything.
The same three bands that govern agent behavior (act, escalate, halt) also govern evaluation severity.
Same band. Gap exists but the action wouldn’t change. Score was 92, recalculated to 83. Both say “act.” Log it. Track the trend. No intervention.
Adjacent crossing. Gap crossed one threshold. What should have been “act” was really “escalate.” Flag for review. Check who consumed this metric. Assess downstream impact.
Skip-band crossing. Gap jumped two bands. What should have been “act” was really “halt.” Persona-weighted audit triggers immediately. If a VP consumed this metric and acted on it, you have a potential anti-evangelist event.
One framework powers both the trust layer and its own accountability system. The evaluation layer grades the trust layer using the same rules the trust layer uses to govern agents. That’s architectural consistency, not coincidence.
Closing the loop with the sixth signal
In the previous article, I described five trust signals: lineage, freshness, ownership, usage, and discoverability. Four of those are static. They only change through manual updates or upstream events. Usage absorbs interaction data, but it only measures volume. How many teams query this metric. Not whether those teams actually trusted the answer.
That means the flywheel I described, where more deployments generate better governance rules, had no mechanism to actually improve trust scores from consumption patterns. The loop wasn’t closed.
Consumption confidence is the sixth signal that closes it.
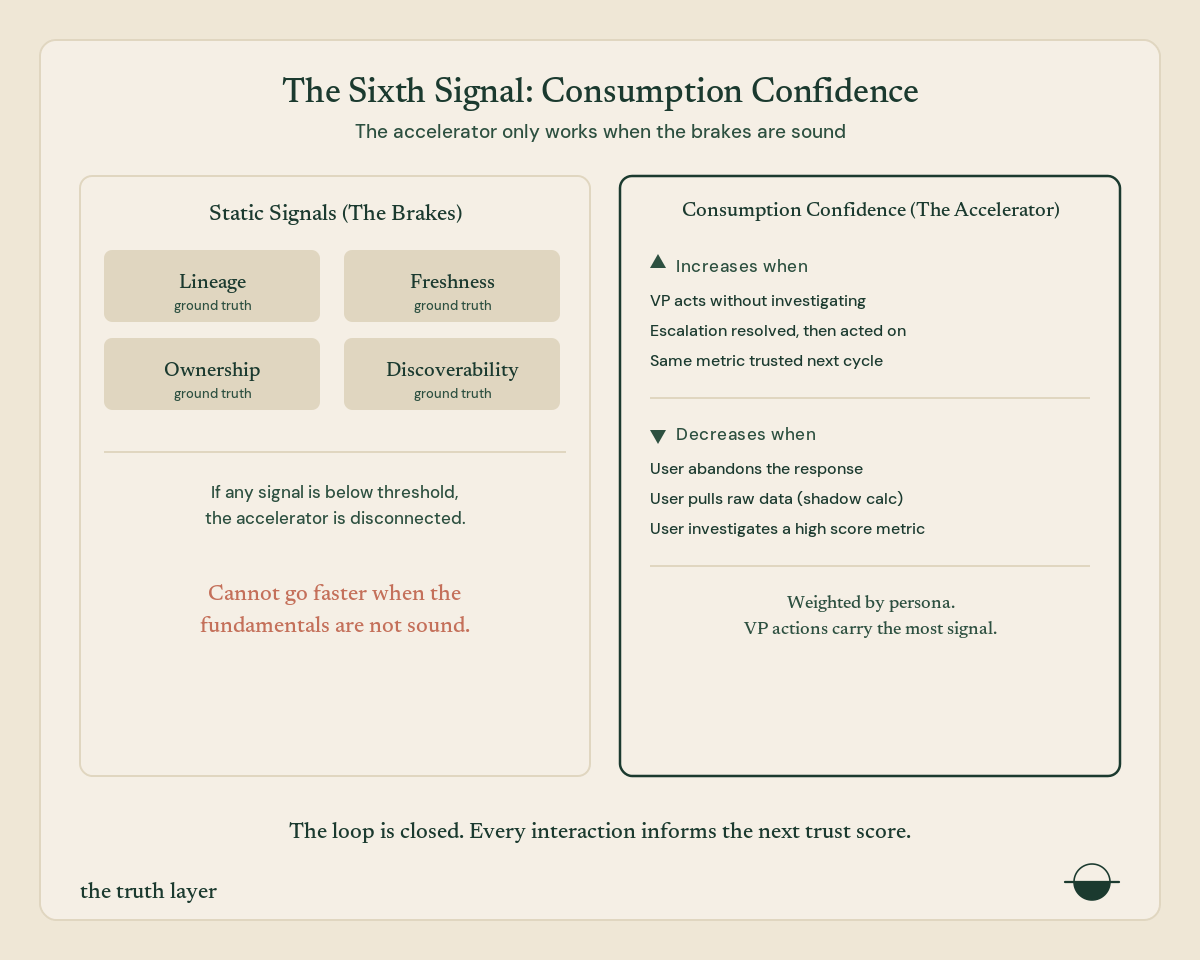
It measures what happens after the query. Three behaviors increase it: the user acts without investigating, an escalation gets resolved and then acted on, the user returns to the same metric next cycle without re-verifying. Three behaviors decrease it: the user abandons the response, the user pulls raw data to verify (shadow calculation), the user investigates a metric the score said was safe.
Weighted by persona. A VP acting without hesitation carries more signal than an intern investigating everything. Investigation is expected from an intern. From a VP, it means the score didn’t match their intuition.
But consumption confidence comes with a critical safeguard. It can only raise the composite trust score if the static signals are healthy. If any ground-truth signal (lineage, freshness, ownership, discoverability) is below its individual minimum threshold, consumption confidence is capped. It cannot compensate for broken fundamentals.
Think of consumption confidence as the accelerator and the static signals as the brakes. If the brakes are off, the accelerator is disconnected. The system won’t let you go faster when the fundamentals aren’t sound.
Without this safeguard, you get a false trust spiral. A VP mandates usage. Consumption confidence climbs. Trust score rises. Meanwhile the pipeline is stale, the owner bounced, and nobody catches it because the score keeps climbing from social proof. A month later, the org discovers every action was taken on bad data. The accelerator/brakes design prevents exactly this scenario.
The closed loop
With consumption confidence added, the full architecture looks like this:
A metric gets defined with a trust contract (five static signals). The trust score is calculated and consumption confidence is initialized. An agent retrieves the metric. A consumer receives the response. They act, investigate, abandon, or shadow-calculate. That interaction streams to the evaluation service. The service classifies the signal by type (internal, external, adversarial), persona weight (VP, analyst, intern), and recalculation tier (immediate, short cycle, routine). Consumption confidence recalculates. The updated trust score feeds the next response. The next consumer gets a score informed by every prior consumer’s behavior.
Steps 1 through 5 are a static platform. Steps 6 through 11 are the learning flywheel. The loop is now closed. Every trust score is a testable prediction. Every action is a test of that prediction.
I built an evaluation simulator that demonstrates this. Trigger a silent pipeline failure and watch the trust score stay green while the data underneath degrades. Then watch consumption confidence detect the problem from behavioral signals before anyone files a ticket.
This is the third article in “The Truth Layer” series. The first explored why 28% of US firms don’t trust the data feeding their AI agents. The second showed what trust contracts look like in practice. Next: how context engineering determines whether your trust signals survive the agent’s reasoning window.
The agent did its job. The data lied. Nothing in your stack was watching for it.
That’s gap two. And that’s what we’re building for.